order by 的内部实现有两种: 全字段排序 和 rowid排序。
按是否需要 磁盘临时文件 辅助排序可分为:内存排序 和 外部排序。
按是否需要 临时表 辅助排序可分为:内存临时表 和 磁盘临时表。
查看是否需要排序
当 explain 中的 Extra 字段显示 Using filesort,表示该查询需要排序。
注:只是表示需要排序,这里不区分是在内存还是磁盘,别被
filesort误导。根据数据量和sort_buffer大小,可能是内存排序,也可能是外部排序(需要借助磁盘临时文件辅助排序)。
MySQL 会为每个线程分配一块内存用于排序,称为 sort_buffer。对应的参数为 sort_buffer_size ,顾名思义为 sort_buffer 的大小。默认值为256k,最小可设为32k。
排序实现
可通过 optimizer_trace 中的 filesort_summary 中的 sort_mode 来确定排序采用了哪种实现逻辑。
1
2
3
4
# 只对当前session生效
1.set optimizer_trace = 'enabled=on';
# 这两句必须一起执行才能看到 `OPTIMIZER_TRACE` 输出,而且只能在命令行中使用,datagrip中看不到输出
2.执行sql;SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
截取 optimizer_trace 部分输出(在末尾部分)如下:
为了演示外部排序,将
sort_buffer_size设为了最小值 32768(32k),
1
2
3
4
5
6
7
8
9
10
11
12
"filesort_summary": {
"memory_available": 32768,
"key_size": 8,
"row_size": 39,
"max_rows_per_buffer": 840,
"num_rows_estimate": 18446744073709551615,
"num_rows_found": 20211,
"num_initial_chunks_spilled_to_disk": 21,
"peak_memory_used": 35384,
"sort_algorithm": "std::sort",
"sort_mode": "<fixed_sort_key, packed_additional_fields>"
}
memory_available 即为排序可使用的内存大小,和上面设置的 sort_buffer_size一致。
peak_memory_used 表示排序过程中的峰值内存使用大小,可见大于 sort_buffer_size,内存装不下了,只能使用外部排序,借助磁盘临时文件来辅助排序。
num_initial_chunks_spilled_to_disk 即为排序过程中使用的临时文件数,可见此次排序使用了21个临时文件,使用归并排序算法。
num_rows_found 表示有 20211 行数据参与了排序。
sort_mode 总共有3种情况,说明了在 sort_buffer 中包含了哪些内容:
-
<sort_key, rowid>: This indicates that sort buffer tuples are pairs that contain the sort key value and row ID of the original table row. Tuples are sorted by sort key value and the row ID is used to read the row from the table.即 rowid排序,意思是排序时只使用了排序字段和rowid,目的是为了装入更多数据,尽量使用内存排序。自然,为了获取其他字段内容,还需要根据rowid回表查询。
对于有主键的Innodb表,
rowid就是主键;对于没有主键的Innodb表,系统会生成一个6字节的rowid作为主键。在 8.0.20 之前,还有一个参数:
max_length_for_sort_data,默认值为4096,用于控制排序的行数据长度。如果单行数据长度超过这个值,MySQL就会由全字段排序转为使用rowid排序。从 8.0.20 开始,
max_length_for_sort_data由于优化器的调整已经过时了,设置这个参数将不会有任何作用。MySQL的一个设计思想是能用内存就用内存,对于Innodb表来说,会优先选择全字段排序,因为不需要回表(当数据页不在内存中时,回表还是需要读磁盘),结果集直接就从
sort_buffer返回了。rowid排序是第二选择。如果转成rowid排序内存还放不下的话,最后会转成外部排序。 -
<sort_key, packed_additional_fields>: Like the previous variant, but the additional columns are packed tightly together instead of using a fixed-length encoding.即全字段排序,
sort_buffer中包含了排序的字段和查询引用到的全部字段(因此叫做全字段排序),结果集会直接从sort_buffer中返回。packed表示排序过程由于sort_buffer紧张(见上图),对字符串做了“紧凑”处理,在排序过程中是按照字段实际长度来分配空间的。 -
<sort_key, additional_fields>: This indicates that sort buffer tuples contain the sort key value and columns referenced by the query. Tuples are sorted by sort key value and column values are read directly from the tuple.同上,只是没有了
packed。示例:
将
sort_buffer_size恢复为默认值:262144(256k),再看看有什么变化:1 2 3 4 5 6 7 8 9 10 11 12 13
"filesort_summary": { "memory_available": 262144, "key_size": 8, "row_size": 35, "max_rows_per_buffer": 1001, "num_rows_estimate": 18446744073709551615, "num_rows_found": 20211, "num_initial_chunks_spilled_to_disk": 0, "peak_memory_used": 43043, "sort_algorithm": "std::stable_sort", "unpacked_addon_fields": "using_priority_queue", "sort_mode": "<fixed_sort_key, additional_fields>" }
可看到
peak_memory_used<memory_available,说明sort_buffer完全够用了,直接在内存排序即可,num_initial_chunks_spilled_to_disk为0,表示不需要借助磁盘临时文件来辅助排序。而且
sort_mode中也没有了packed,因为内存空间已经完全够用了,不再需要做“紧凑”处理了。
排序提速
从上面分析可以看出,排序是个代价比较高的操作,尤其是当转成外部排序时,会涉及到多次磁盘IO。
所以尽量使用内存排序是最优解,对应可调整的参数是 sort_buffer_size。那还有没有更进一步的优化?
很明显,借助索引,可以完全避免排序。
比如这样一句sql:
1
select * from t where city = 'xxx' order by name limit 1000;
便可以建立一个 (city,name) 的联合索引,那么在 (city,name) 这棵索引树上便是先按 city 排序,再按name 排序(即 city 相同时 name 局部有序)。
这样的话只需先快速定位到 city,然后依次往后遍历取出 id,再回表取出整行数据,作为结果集的一部分直接就返回了,完全避免了排序。而且,由于是有序的,对于 limit 来说更友好,不再需要遍历所有 city=xxx 的数据了,遍历到第1000条便可直接结束了(explain 中的 rows 不准)。
更进一步,如果查询没必要获取全部字段,则可利用到覆盖索引,直接从索引树获取到全部字段,连回表查询都不用了。
如上面的 sql 可改为:
1
select city,name,age from t where city = 'xxx' order by name limit 1000;
此时建一个 (city,name,age) 的联合索引,即可满足排序需求,又不需要回表查询,此时是最优解。
当然,还是那句老话,维护索引有代价,需综合考虑。
实例
假设维护一个人员信息表,现已有索引 (city,name) ,问以下查询是否需要排序?
1
select * from t where city in (A,B) order by name limit 100;
虽然已有 (city,name) 索引,但只能保证同一 city 内 name 有序,不同 city 之间 name 仍然是无序的。所以该查询在数据库内部仍然需要排序。
如果出于种种原因想要避免在数据库内部排序,有什么办法?
那就在应用端排序,把一条sql拆为两句:
1
2
select * from t where city = A order by name limit 100;
select * from t where city = B order by name limit 100;
拆开的查询可以利用到索引,不需要排序。
在应用端便可得到两个有序数组,使用归并排序合并为一个有序数组后,取前100即为结果集。
如果是分页查询呢,比如:
1
select * from t where city in (A,B) order by name limit 10000,100;
还是和上面的思路一样,拆分为2个查询:
1
2
select * from t where city = A order by name limit 10100;
select * from t where city = B order by name limit 10100;
同样使用归并算法得到一个有序数组,取第 10000 ~ 10100 的值即为结果集。
这时的问题是数据量太大,如果应用端内存紧张的话,可考虑只查询 id 和 name:
1
2
select id,name from t where city = A order by name limit 10100;
select id,name from t where city = B order by name limit 10100;
该查询不需排序,且会用到覆盖索引,也不用回表。合并得到有序数组后,取出第 10000 ~ 10100 的 id,再拿这100个 id 去数据库查出所有记录即可。
随机排序
order by rand()
随机排序在现实中的应用场景还是比较多的,可能会首先想到使用order by rand() 。
比如:
1
select * from words order by rand() limit 3;
表示从单词表中随机抽取3个单词。
虽然用法简单明了,但它的执行效率怎样(对于数据量不是特别大的表,其实也完全够用了),做个实验。
先构造一张 words 表和实验数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
CREATE TABLE `words` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=0;
while i<10000 do
insert into words(word) values(concat(char(97+(i div 1000)), char(97+(i % 1000 div 100)), char(97+(i % 100 div 10)), char(97+(i % 10))));
set i=i+1;
end while;
end;;
delimiter ;
call idata();
explain 下看看:

Extra 显示 Using temporary; Using filesort ,表示需要临时表,需要排序。
注:需要和上面讲到的临时文件区分开来,临时表和临时文件是两个东西。
为什么需要临时表?
order by rand() 的实现逻辑是为每一行数据生成一个随机数,然后按这个随机数来排序,以达到随机排序的目的。所以需要一张临时表来存放这个新生成的随机数字段。
再次强调,Using filesort 只是表示需要排序,有可能是内存排序,也有可能是外部排序。不要看它的名字是 filesort,就认为一定是外部排序。
它的整个流程是这样的:
- 生成一张内存临时表。扫描
words表,将word字段和生成的随机数存入临时表; - 将
word字段和随机数放入sort_buffer排序; - 从
sort_buffer中取出前3个word,作为结果集返回。
可通过 optimizer_trace 验证一下:
1
2
set optimizer_trace='enabled=on';
select * from words order by rand() limit 3;select * from information_schema.OPTIMIZER_TRACE\G
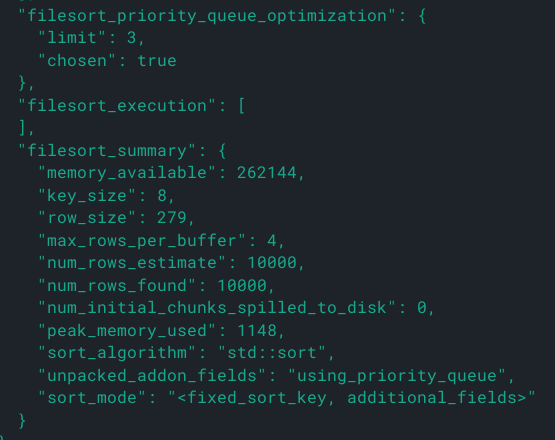
可看到该排序使用了全字段排序,且没有使用到磁盘临时文件。sort_buffer 中同时最多有4行数据存在,每一行长度为 $8+279=287$。为什么只有4行?难道不应该是对10000行数据排序吗?
答案是filesort_priority_queue_optimization中 chosen 为 true,表示使用了优先级队列排序(即堆排序)。因为只需要 limit 3,相当于求 top3,剩下9997条数据并不需要排序,堆排序完美适合解决这个问题。
大顶堆求 top k 小,小顶堆求 top k 大。而且最后堆顶元素就是第k大(小)元素。
比如数据集为[0.9,0.4,0.5,0.7,0.3,0.8],利用大顶堆求top3小:
- 建立初始堆:[0.9,0.4,0.5],0.9为堆顶元素;
- 插入0.7,比0.9小,交换,0.7为最大元素,堆无需调整,此时堆为 [0.7,0.4,0.5];
- 插入0.3,比0.7小,交换,0.3下沉堆化,此时堆为 [0.5,0.4,0.3];
- 插入0.8,比0.5大,无需交换,堆不变,此时堆为 [0.5,0.4,0.3];
- 遍历结束,top3小即为 [0.5,0.4,0.3],且0.5为第3小的元素。
自己实现随机排序
方法一
随机取一行的算法如下:
- 取得主键 id 的最大值M和最小值N
- 用随机函数生成一个介于M和N之间的数 $X=(M-N)*rand()+N$
- 取 $≥X$ 的第一个 id 的行
用sql表示如下:
1
2
3
select max(id),min(id) into @M,@N from t;
set @X = floor(@M-@N)*rand()+@N;
select * from t where id >= @x limit 1;
max(id) 和 min(id) 都不需要扫描索引,第三步的 select 也可以用索引快速定位,速度很快。
但是有个致命缺陷,它不是真正的随机。如果 id 是连续的没问题,但如果 id 之间有空洞,则选择不同行的概率不一样。
如 [1,2,4,5],按这个算法,4 被选中的概率是其他的两倍。但是它速度最快。
方法二
- 取得整个表的行数,记做 C
- $Y = floor(C*rand())$
- limit Y,1
limit Y,1 的处理逻辑是按顺序一行行读出来,丢掉前Y个,取下一个作为结果返回(可通过慢查询日志的 Rows_examined 验证)。
这里可能会有点疑问,为什么不走主键索引树,直接快速定位到 Y不就行了。
这是想当然了,因为并不知道第 Y 行的主键id是多少呀,除非只有当主键id从1开始连续递增才行(第Y行的主键id就是Y)。
所以该算法总共扫描的行数为:$C+Y+1$ ,执行代价比方法一要高一些,但跟 order by rand() 比起来还是快得多,而且严格随机。
那么用该算法解决随机获取3个单词的步骤如下:
- 取得整个表的行数,记做 C
- $Y1 = floor(Crand()), Y2 = floor(Crand()), Y3 = floor(C*rand())$
- limit Y1,1;limit Y2,1;limit Y3,1
总共需扫描 $【C+(Y1+Y2+Y3)+3】$ 行 。
其实还有进一步优化的空间,因为Y1、Y2、Y3 重复扫描了:
取得 Y1、Y2、Y3后,设最大值为M,最小值为N,执行
1
select * from t limit N,M-N+1
从结果集中取第一条、最后一条、(Y2-Y1)条即可。
改进后扫描行数为 $C+M+1$,大大减少了扫描行数。
不可一味盲目追求极致解,够用就好!!!