MySQL中的锁有三类:全局锁、表级锁、行级锁
全局锁
即给整个数据库实例上锁,让整个库都处于只读状态,除查询以外的操作都会被阻塞。server层实现。
如果加上全局锁后,客户端由于异常断开,MySQL会自动释放这个锁。
加锁:
1
2
3
flush tables with read lock;
或
flush table t with read lock;
解锁:
1
unlock tables;
使用场景:做全库逻辑备份
隐患:
- 由于只能查询,所以在此期间业务基本停摆
- 如果在主库上备份,业务停摆;如果在备库上备份,在此期间备库不能执行从主库同步过来的 binlog,会导致主从延迟
那如果备份的时候不加全局锁会发生什么情况呢?
不加锁,会导致备份出来的库不是同一个逻辑时间点的,数据从业务逻辑上看是不一致的。
比如在备份过程中先备份了A表,然后执行了一个业务操作,这个业务操作会同时更新A表和B表,再备份B表。那么这个时候备份出来的数据A表还是老版本,而B表已经被更新了,这个备份就是有问题的,是逻辑不一致的。
为了既不影响业务,也要保证备份视图的逻辑一致性,推荐采用另一种全库备份的方法:mysqldump -single-transaction。导数据之前会启动一个事务,来确保拿到一致性视图。而且由于 MVCC 的支持,在此期间是可以正常更新的。
当然显而易见,这种方法只适用于支持事务的存储引擎,所以这也是为什么推荐使用 Innodb 而不是 MyISAM 的一个原因。
表级锁
server层实现,分两种:元数据锁(MDL)和表锁。
表锁
与全局锁一样,也会在客户端断开时自动释放
加锁:
1
lock tables t1 read,t2 write;
解锁:
1
unlock tables;
以上述加锁语句为例,t1加了读锁,t2加了写锁:
- 任何线程都不能写 t1 ,包括本线程
- 只有本线程能读写 t2
- 本线程甚至不能访问除 t1、t2 之外的任何表,这点很奇怪,不懂为什么这么设计,访问其他表时会报错
Table 'xxx' was not locked with LOCK TABLES
元数据锁
Meta data lock,MDL
不需要显示使用,访问表的时候会自动加上。
从MySQL5.5开始引入,当做增删查改时,会加MDL读锁;当变更表结构时,会加MDL写锁。
-
读锁不互斥,因此可以有多个线程同时对一张表增删改查
-
读写互斥,即不能有多个线程同时更改表结构,或一个线程在增删改查而另一个线程在更改表结构
-
MDL锁在事务提交时才会释放,在变更表结构时要特别小心,以免锁住线上的查询和更新,导致整张表不能读写。下面是一个示例:
session A session B session C session D begin; select * from t limit 1; select * from t limit 1; alter table t add f int; select * from t limit 1; session A 先开启了一个事务,执行了一次查询,并且没有马上提交,这时会对表 t 加一个 MDL 读锁。
session B 也需要一个 MDL 读锁,读锁之间不互斥,可以正常执行查询。
session C 要加一个字段,需要一个 MDL 写锁,读锁和写锁互斥,所以必须等待表 t 释放读锁之后才能继续。
session D 需要一个读锁,这里需要注意的是,表 t 上会有一个等待获取锁的锁队列,而获取MDL写锁的优先级要比获取读锁的优先级高,所以导致session D 也被阻塞。
最后的结果就是表 t 完全被锁住,完全不可读写了。如果客户端还有重试机制,一直在发起重试请求,MySQL的线程很快就会爆满,最后导致整个实例挂掉。
解决办法:
1、监控长事务(information_schema.innodb_trx),要么先暂停DDL,要么kill掉这个长事务
2、但是对于一些热点表,kill未必管用,可能刚kill掉一个长事务,新的请求立马又来了。这种情况下,理想的办法是为 alter table 语句设定等待时间,如果在此期间能拿到MDL写锁最好,拿不到也不要阻塞后面的业务语句,先放弃。之后再重试这个命令来重试这个过程。MariaDB 和 AliSQL 已经提供了这个功能,MySQL暂时没有。
1
2
ALTER TABLE t NOWAIT add column ...
ALTER TABLE t WAIT N add column ...
MySQL可以通过调整 lock_wait_timeout 值来控制这个超时时间,默认值是 31536000s,即1年,显然这个时间太长了。
获取元数据锁的超时时间,注意与
innodb_lock_wait_timeout区分开来
案例一
假如正在备库执行一个 -single-transaction 的逻辑备份,此时在主库上对表 t 执行了一个 DDL,备库会出现什么情况?
备库会根据 DDL 的 binlog 到达的时间点不同而出现不同的情况。
先拆解一下 mysqldump -single-transaction 在内部的执行逻辑:
-
set session transaction isolation level repeatable read;
-
start transaction with consistent snapshot;
(其他表的备份逻辑)
-
SAVEPOINT sp;
(时刻1)
-
show create table
t;(时刻2)
-
select * from t;
(时刻3)
-
rollback to savepoint sp;
(时刻4)
(其他表的备份逻辑)
在时刻1到达:没有任何影响,此时表 t 上没有任何 MDL 锁,所以可正常执行,备份得到的是新的表结构;
在时刻2到达:此时已经先备份完了 t 的表结构,DDL才到达,在执行第5步的时候会报错:Table definition has changed,please retry transaction ,mysqldump 终止;
在时刻3到达:此时表结构和数据都已备份完成,但是 MDL 读锁还没释放(会在第6步后才释放),所以 DDL 操作会阻塞,备份得到的是旧的表结构;
在时刻4到达:MDL 读锁已被释放,DDL 可正常执行,备份得到的是旧的表结构。
行锁
由存储引擎实现,Innodb 支持,MyISAM 不支持。如果不支持行锁,就只能使用表级锁,也就意味着锁的粒度太大并发度就会降低。这也是为什么推荐使用 Innodb 的重要原因之一。
两阶段锁
之前提到过一个两阶段提交,行锁有一个两阶段锁协议,也被称为 2PL。
定义
两阶段指的是分为加锁阶段和解锁阶段,在加锁阶段只能加锁不能解锁,在解锁阶段只能解锁不能加锁。
单看定义很难理解,换成大白话说就是行锁在需要的时候才加上,但并不是不需要了就立即释放,而是要事务结束后才会释放。
为什么需要两阶段锁?
重点就是在事务结束后才会释放所有行锁,而不是用完立即释放。任何锁的本质就是保证并发操作的正确性,将并行改为串行。二阶段锁用来保证并发更新操作的正确性,两个并发的更新操作,必须等其中一个提交后另一个才能继续,否则就会发生更新被覆盖的情况。
假设不存在两阶段锁协议,会发生如下情况:
同时发起2个操作,向同一个账户打200块,账户原余额有100块。
- sessionA 发起打款操作,获取到写锁,用
update更新账户余额为 300 update完毕,假设不存在两阶段锁,用完立即释放,释放写锁,此时事务尚未提交- sessionB 发起打款操作,获取到写锁,根据一致性视图可见性规则:事务未提交,更新不可见。得到的账户余额仍为100,用
update更新账户余额为 300 update完毕,立即释放写锁- sessionA 提交,账户余额为 300
- sessionB 提交,账户余额为 300
所以,因为存在两阶段锁协议,在第2步结束后,由于事务尚未提交,写锁仍未释放,则第3步的 update 操作必须等待 sessionA 提交后才能继续,此时 sessionA 读到的余额为300,再执行 update 后更新余额为500,这才是符合逻辑的结果。
如何优化?
锁虽然保证了并发操作的正确性,但是由并行改为串行降低了并发度。所以另一个问题就是如何最大限度的提高并发度?
由于行锁是在需要的时候才加上,在事务结束后统一释放。所以针对包含多个更新的事务,可以调整事务内更新语句的顺序,将会产生行锁竞争的语句尽量往后放,从而让等待行锁的时间最小化,以达到提高并发度的目的。
示例:
假如有一个在线订票业务,订票逻辑可以简化为下列步骤:
- 从账户余额扣掉票钱
- 给系统余额加上票钱
- 记录一条日志
假设同时发起2个订票请求,可以看到,在这个事务中,会产生行锁竞争的是第2步(直白说就是会 update 同一行)。按这个顺序的话,系统余额表上的行锁会从第2步开始加上,第3步完成后事务提交时释放。
调整下顺序,改为:
- 记录一条日志
- 从账户余额扣掉票钱
- 给系统余额加上票钱
这时候系统余额表上的行锁持续时间就缩短为1步了,从第3步开始加上,到第3步完成后事务提交时释放。
虽然在这里看就是少了一小步(一条语句的执行时间),但如果这个业务请求并发量很大的话,这个优化的效果就会非常明显。
死锁
为什么会出现死锁?
简单说就是出现锁的循环等待。示例如下:
| sessionA | sessionB | |
|---|---|---|
| 1 | begin; | begin; |
| 2 | update t set k = k+1 where id=1; | |
| 3 | update t set k = k+1 where id=2; | |
| 4 | update t set k = k+1 where id=2; | |
| 5 | update t set k = k+1 where id=1; |
由于事务都尚未提交,行锁还未释放。第4步要获取 id=2 的行锁,需要等待sessionB提交;第5步要获取 id=1 行锁,需要等待sessionA提交,死锁产生了。
解决办法
-
等待直到超时,然后退出
Innodb中有个参数用于设置这个超时时间:
innodb_lock_wait_timeout,默认值为 50s。这个默认值对于业务来说是不能接受的,相当于卡顿50s。但是如果设成较小的值,又很有可能造成误伤:如果不是死锁,而就是普通的锁等待,此时并没有循环等待的情况,但是由于超过了阈值而被当成了死锁而提前退出了。所以这种方法一般不采用。 -
主动死锁检测
innodb_deadlock_detect用于控制是否打开主动死锁检测,默认是 ON。这是一种相对较好的方式,但需要注意的是它的资源消耗有可能会很大。对于每个新加入进来的线程,都要先判断会不会由于自己的加入而导致死锁,这是一个时间复杂度为 O($n^2$) 的操作。假设有1000个并发线程同时更新同一行,这个死锁检测就是100万量级的。
虽然最终检测的结果是没有死锁,但此期间需要消耗大量的CPU资源。所以当出现CPU消耗接近100%,TPS却很低的话,很有可能就是死锁检测导致的。
那如何优化这种热点行更新问题?
- 简单粗暴的方法就是如果确认不会出现死锁,直接关闭死锁检测。但这个方法明显危险系数很高,万一还是出现了死锁的话只能依靠超时机制,而如上面所述,超时机制的阈值很难设置。
- 拆分热点行。将一行拆分为多行,比如一条账户记录可以拆分为10条子账户记录,账户总额就等于10条子账户余额之和,在需要更新账户余额时,随机选择其中一条进行更新。这样就将一行上的死锁检测成本、锁等待个数、冲突概率都降为了原来的1/10。这种方案属于设计层面上的优化,需要结合业务逻辑做详细的设计和测试。
案例二:删除大量数据
现需要删除前10000行数据,有以下三种方式:
-
delete from t limit 10000; -
在一个连接中循环执行20次
delete from t limit 500; -
在20个连接中同时执行
delete from t limit 500;
哪种方式好一些?
第一种:执行时间较长,意味着占用锁(MDL读锁、X锁)的时间会比较长;而且大事务在从库上回放的时间也较长,在此期间会导致主从延迟;
第三种:人为的制造了行锁冲突,而且大概率会重复删除,达不到删除前10000行数据的目的;
第二种方式较好。
案例三:查询长时间不返回
主要思路:通过 show processlist 查看当前语句处于什么状态,一般是被锁住了。
等MDL锁
当有其他线程持有MDL写锁时,就会把查询堵住。
比如以下场景:
| sessionA | sessionB |
|---|---|
| lock table write; | |
| select * from t where id=1; |
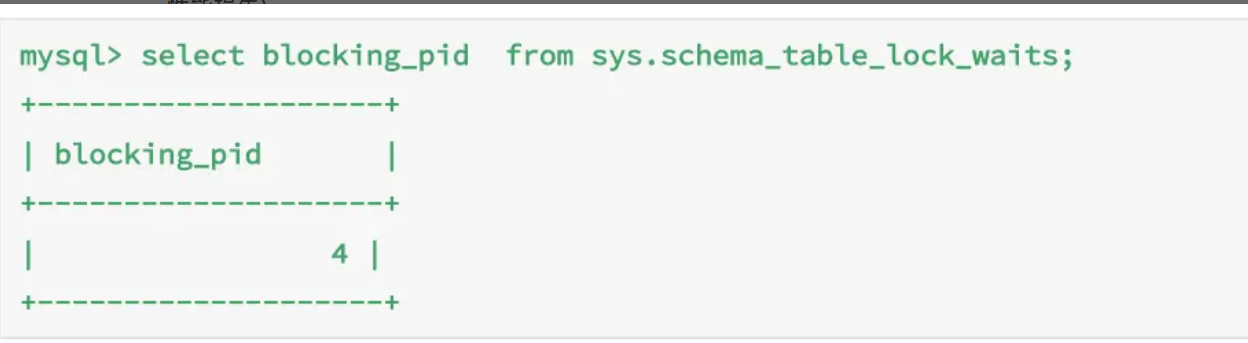
show processlist 表现如下:

可看到状态为 Waiting for table metadata lock。
解决办法很简单,谁持有MDL写锁,就把它 kill 掉。
但有时候从 show processlist 中不容易看出,可查询 sys.schema_table_lock_waits表,前提是 performance_schema=on,这个选项在MySQL8中默认开启,相对于不开启大约有 10% 的性能损失。
或者也可以通过 sys.innodb_lock_waits 查询:
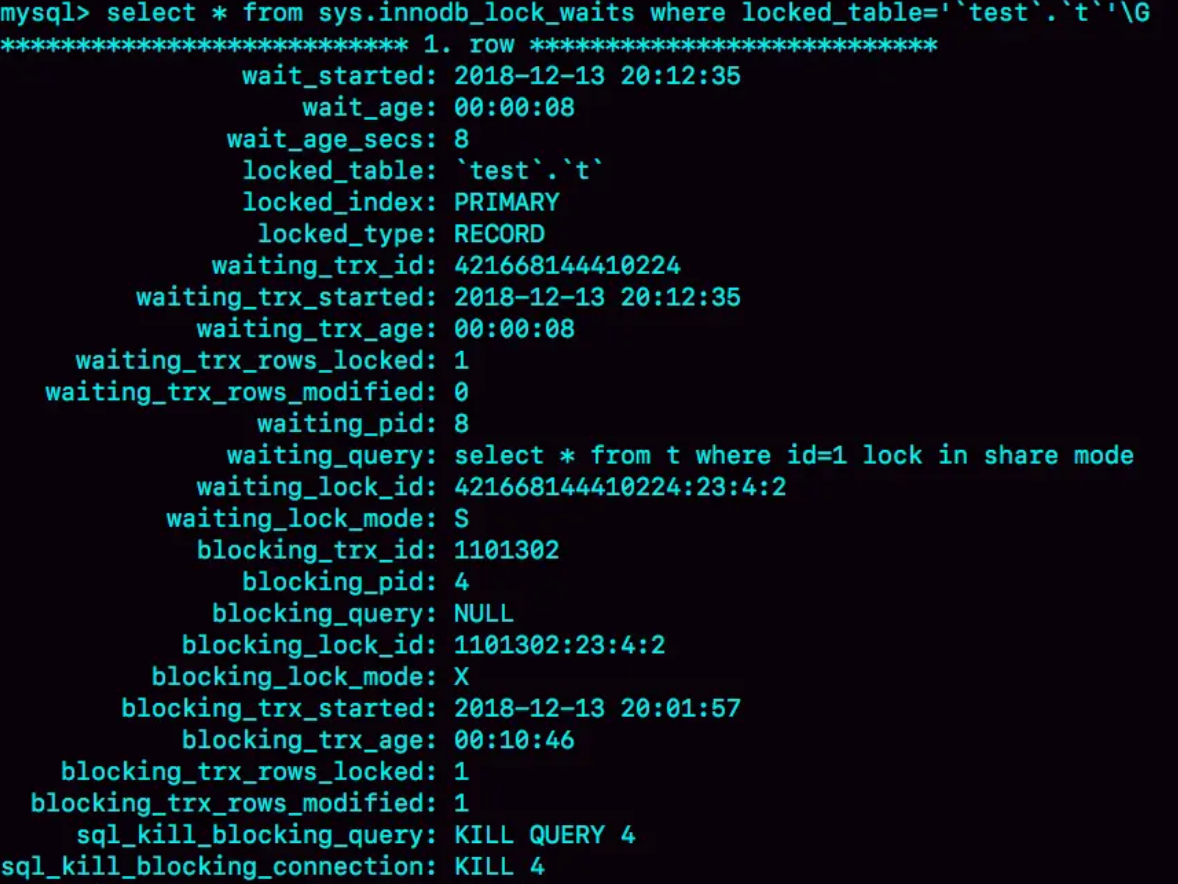
需要注意 kill query 4 和 kill 4 的区别:
kill query 4:表示停止4号线程当前正在执行的语句。有时候这个命令可能没用,因为语句可能已经执行完了,但事务没提交导致锁不能释放。kill 4:直接断开连接,连接断开时会自动释放锁。
等行锁
这比较普遍:
| sessionA | sessionB |
|---|---|
| begin; | |
| update t set c=c+1 where id=1; | |
| select * from t where id=1 lock in share mode; |
由于 sessionA 事务未提交,导致 id=1 的写锁不能释放,而 sessionB 的查询需要读锁,所以会被堵住。
next-key lock
目的:解决幻读问题
什么是幻读?
The so-called phantom problem occurs within a transaction when the same query produces different sets of rows at different times. For example, if a
SELECTis executed twice, but returns a row the second time that was not returned the first time, the row is a “phantom” row.
即一个事务在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的行。
幻读专指新插入的行。
一个幻读示例:
假设存在 person(id,name) 表,含2条数据:(1,”foo”)、(2,”bar”)
| 事务A | 事务B |
|---|---|
| select count(1) from person 查到2条数据 | |
| insert into person(id,name) values(3,”zoo”) 插入一条数据 | |
| commit 提交 | |
| insert into person(id,name) values(3,”zoo”) 插入一条数据,报错提示主键重复 | |
| select * from person where id = 3,又查不到数据,但是又不能insert,就很奇怪 |
解决办法:使用 for update 加 next-key lock。
next-key lock 定义:行锁 + 间隙锁 ,前开后闭区间
To prevent phantoms,
InnoDBuses an algorithm called next-key locking that combines index-row locking with gap locking.InnoDBperforms row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on the index records it encounters. Thus, the row-level locks are actually index-record locks. In addition, a next-key lock on an index record also affects the “gap” before the index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record. If one session has a shared or exclusive lock on recordRin an index, another session cannot insert a new index record in the gap immediately beforeRin the index order
间隙锁
间隙锁即用来锁住行之间的间隙,换句话说,可以锁住 “不存在” 的行,也就是 insert 操作。
间隙锁之间并不冲突,与间隙锁冲突的是 insert 这个操作。两个会话可以同时执行 select * from t where c=7 for update,说明两个会话都获取到了同一个间隙锁,但如果此时有 insert 操作就会被阻塞。
注:
insert操作并不单指 sql 中的 insert,而是广义上的索引树上的所有插入行为。
RC 和 RR 在锁问题上的区别
RC可以禁用间隙锁,RC下只有行锁。
而且RC级别下在语句执行完毕后,就会把“不满足条件”的行锁释放,不需要等到事务提交。RR级别下所有的加锁资源都是在事务提交或回滚时统一释放。
比如表 t(id,c),id是主键,c 是普通字段。
将隔离级别设为RC,执行 select * from t where c = 5 for update,由于需要扫描主键索引树,会给所有扫描到的行都加上行锁。但是在这句语句执行完毕后,无需事务提交便会把所有 c!=5 的行锁都释放,此时其他事务便可对所有 c!=5 的行进行更新操作。
同样的实验如果将隔离级别设为RR便会发生阻塞,因为RR级别下所有的锁都是在事务提交时才会释放。
所以 RC 级别下,锁的范围更小,锁的时间更短,在业务允许的情况下隔离级别设为RC可以提高并发度。
当设为RC后,Innodb 会强制要求将 binlog_format 设为 ROW,这是为了保证数据和binlog日志的一致。以下文综合案例中的表和数据举例:
| sessionA | sessionB |
|---|---|
| begin; select * from t where d=5 for update; update t set d=100 where d=5; |
|
| update t set d=5 where id=0; update t set c=5 where id=0; |
|
| commit; |
在RC级别下,语句执行完就会释放所有 d!=5 的行锁,而且没有间隙锁,因此 sessionB 不会阻塞。
执行完毕后数据变为:(id=0, c=5, d=5)、(id=5, c=5, d=100)。
如果 binlog_format 为 statement,那么在 binlog 中会产生类似如下日志:
- update t set d=5 where id=0;
- update t set c=5 where id=0;
- update t set d=100 where d=5; #事务提交时才会写入日志,所以它出现在了最后
使用该日志恢复出来的数据变成了:(id=0, c=5, d=100)、(id=5, c=5, d=100)。可以发现,恢复出来的数据和数据库里的数据不一致,这肯定是不行的。
改为 row 以后,binlog中的日志类似如下,可使用 mysqlbinlog --base64-output=decode-rows -vv 查看:
1
2
3
4
5
6
7
8
9
### UPDATE `test`.`t`
### WHERE
### @1=0
### @2=0
### @3=0
### SET
### @1=0
### @2=0
### @3=5
1
2
3
4
5
6
7
8
9
### UPDATE `test`.`t`
### WHERE
### @1=0
### @2=0
### @3=5
### SET
### @1=0
### @2=5
### @3=5
1
2
3
4
5
6
7
8
9
### UPDATE `test`.`t`
### WHERE
### @1=5
### @2=5
### @3=5
### SET
### @1=5
### @2=5
### @3=100
可看到日志恢复出来的数据和数据库里的数据是一致的。
事实上,statement 的 binlog 由于是基于 sql 语句的日志,在保持数据和日志一致性上会有很多问题,比如 now() 函数。因此推荐使用 ROW 的binlog,这也是 MySQL8 的默认配置。
综合案例:加锁规则
以下规则适用于 5.x 系列 ≤ 5.7.24, 8.x系列 ≤ 8.0.13。其他版本需实践验证,可能会有微调。
且都是在可重复读默认级别下,这个前提非常重要,其他级别如读提交有不同的处理。
2个原则,2个优化,1个bug:
- 原则一:加锁的基本单位是
next-key lock,前开后闭区间 -
原则二:查找过程中访问到的才会加锁
-
优化一:唯一索引等值查询,
next-key lock会退化成行锁 -
优化二:索引等值查询,向右遍历且最后一个值不满足等值条件时,
next-key lock退化成间隙锁在 8.0.26 版本中,唯一索引的范围查询,向右遍历且最后一个值不满足条件时,
next-key lock也会退化成间隙锁。具体从哪个版本开始修复的,尚未确定。见示例三。
-
一个bug:唯一索引上的范围查询会访问到第一个不满足条件的值为止
在 8.0.26 版本中已修复,具体从哪个版本开始修复的,尚未确定。见示例五。
以下示例基于:
1
2
3
4
5
6
7
8
9
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),(10,10,10),(15,15,15),(20,20,20),(25,25,25);
示例一:等值查询间隙锁
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; update t set d=d+1 where id=7; |
||
| insert into t values(8,8,8) | ||
| update t set d=d+1 where id=10; |
分析:
- 根据原则二:访问到的都加锁。id 是主键索引,能快速定位到
id=5这条记录,向右遍历下一条记录发现id=10≠7,遍历结束; - 根据原则一:加锁的基本单位是
next-key lock。所以 sessionA 的加锁范围是(5,10]; id=8位于加锁范围内,所以 sessionB 会阻塞;- 根据优化二:索引等值查询,向右遍历且最后一个值不满足等值条件时(这里就是10),
next-key lock退化成间隙锁。所以(5,10]会退化成(5,10),因此 sessionC 不会被阻塞。
这里优化一不适用,因为不存在 id=7 这行记录,因此没有办法退化成行锁。
示例二:非唯一索引等值锁
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; select id from t where c=5 lock in share mode; |
||
| update t set d=d+1 where id=5; | ||
| insert into t values(7,7,7) |
分析:
- 根据原则一得出 sessionA 的加锁范围是
(0,5](行锁 + 行之前的间隙锁); - 根据优化二向右遍历直到 c=10停止,先是 next-key lock
(5,10],然后退化成间隙锁(5,10); - 所以 sessionA 的加锁范围是
(0,5]加上(5,10); - 因此 sessionC 会阻塞;
- 那为什么 sessionB 不会阻塞?按理说 sessionB 需要 id=5 这一行的行锁,同样应该被阻塞才对。 原因在于 sessionA 的查询用的是覆盖索引,不需要回表。而根据原则二:访问到的才加锁。所以锁只会加在 c 索引树上,而 sessionB 的条件是
id=5,走的是主键索引,因此不会被阻塞。
但如果 sessionA 换成 for update 就不一样了, for update 会同时给主键索引上满足条件的行上锁,而 lock in share mode 如果有覆盖索引的情况下只会给覆盖索引上锁。
所以,如果使用的是 lock in share mode 加锁的话,为了避免数据被更新,需要绕过覆盖索引的优化:在查询字段中加入索引中不存在的字段,让查询回表,如改成 select d from t where c=5 lock in share mode; 。
示例三:主键索引范围锁
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; select * from t where id>=10 and id<11 for update; |
||
| insert into t values(8,8,8); insert into t values(13,13,13); |
||
| update t set d=d+1 where id=15; |
sessionA 的查询在逻辑上和 select * from t where id=10 是一致的,但是加锁范围却有很大区别。
分析:
-
初步分析,sessionA 的加锁范围是
(5,10]+(10,15];id>=10是等值查询,会先定位到id=10这行记录,会先加一个 next-key lock(5,10];id<11是范围查询,会向右遍历到id=15停止,发现不满足条件,于是再加一个 next-key lock (10,15]。 -
根据优化一:唯一索引等值查询会退化成行锁。所以
(5,10]会退化成id=10 的行锁; -
综上,sessionA 的加锁范围是
id=10 的行锁+(10,15]; -
因此,sessionB 的第一条语句可正常执行,第二条语句会被阻塞;
-
sessionC 的语句也会被阻塞。
以上示例是在8.x系列 ≤ 8.0.13中验证的。
在 8.0.26 中,
(10,15]退化成了间隙锁(10,15),这条语句不会被阻塞。估计是调整了优化二:不光是普通索引的等值查询,唯一索引的范围查询也是一样,向右遍历到不满足条件的第一个值时,
next-key lock也会退化成间隙锁。具体是哪个版本调整的,尚未确定。见示例四。
示例四:非唯一索引范围锁
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; select * from t where c>=10 and c<11 for update; |
||
| insert into t values(8,8,8); | ||
| update t set d=d+1 where c=15; |
将示例三中 where 字段由 id 改为 c,分析如下:
- 同示例三,初步分析,sessionA 加锁范围是
(5,10]+(10,15]; - 区别在于优化一不适用了,因为不是唯一索引,所以
(5,10]不能退化成行锁; - 所以 sessionB 会被阻塞;
- 由于 c 是普通索引,所以 c 上的范围查询不满足优化二,不会退化成间隙锁。sessionC 会被锁住。
示例五:唯一索引范围锁bug
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; select * from t where id>10 and id<=15 for update; |
||
| update t set d=d+1 where id=20; | ||
| insert into t values(16,16,16); |
基于8.x系列 ≤ 8.0.13。在 8.0.26 版本中已修复,具体从哪个版本开始修复的,尚未确定。
- 初步分析,sessionA 加锁范围是
(10,15](直接就定位到了 id=15 这一行); - id 是主键索引,按理说扫描到
id=15时就可以结束了,因为 id 是唯一的且在主键索引中是递增的,再往后遍历都是 >15 的,不可能满足id<=15。但事实上还会继续往后扫描到第一个不满足条件的值为止,即id=20,所以加锁范围还会加上(15,20]。结果就是导致 sessionB 和 sessionC 都会被锁住。
示例六:非唯一索引上存在“等值”
先插入一条记录:
1
insert into t values(30,10,30);
然后执行以下序列:
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; delete from t where c=10; |
||
| insert into t values(12,12,12); | ||
| update t set d=d+1 where c=15; |
-
delete 和 for update 加锁的逻辑是类似的。sessionA 的加锁范围是
(5,10]+(10,15);注意,现在
c=10的记录在 c 索引树上有两条:(c=10,id=10) 和 (c=10,id=30) ,在这两条记录中间还有一个间隙锁。这个间隙锁只存在于 c 索引树上,主键索引上只有行锁,见第3点。由于这个间隙锁只在 c 索引树上,所以它实际上没有任何作用,因为在两个10之间不存在任何int值,知道这个间隙锁的存在就行。
-
sessionB 会阻塞,sessionC 正常执行。
-
上面讲过 for update 会同时给主键索引上满足条件的行上锁,这里也是一样,因此在主键索引树还有
id=10和id=30两个行锁。
示例七:limit加锁
| sessionA | sessionB |
|---|---|
| begin; delete from t where c=10 limit 2; |
|
| insert into t values(12,12,12); |
示例六的对照示例,按照示例六的分析加锁范围为 (5,10] + (10,15) ,但是由于加了 limit 2,因此在扫描到两行记录,(c=10,id=10) 和 (c=10,id=30) 后便结束了,因此加锁范围变为了 (5,10],所以 sessionB 不会被阻塞。
这个示例也说明了删除数据时尽量使用limit,不仅可以控制删除的条数更安全,而且还可以减小锁的范围。
示例八:降序排序加锁
| sessionA | sessionB |
|---|---|
| begin; select * from t where c>=15 and c<=20 order by c desc lock in share mode; |
|
| insert into t values(6,6,6); | |
| update t set d=d+1 where id=10; | |
| update t set c=c+1 where id=10; |
- 降序排序,整体从右往左扫描。首先定位到
c=20,加上(15,20]的 next-key lock;由于是普通索引,继续向右扫描到c=25,不满足条件c<=20停止,于是再加上(20,25]的 next-key lock,然后退化成间隙锁(20,26); - 向左扫描,直到
c=10不满足条件c>=15停止,于是加上(5,10]的 next-key lock; - 综上,sessionA 在 c 索引树上的加锁范围是
(5,25);因此insert into t values(6,6,6)阻塞; - 由于是
select *,需要回表。虽然在索引c上的扫描范围是 (5,25),但是满足条件的行是c=15、c=20,回表的也是这两行。因此,会在主键索引上加上id=15、id=20两个行锁; - 因此
update t set d=d+1 where id=10不会阻塞;但如果把条件换成c=10就会阻塞,由此可见,锁是加在索引上的,c索引上有c=10的行锁, 主键索引上没有id=10的行锁; update t set c=c+1 where id=10与上一句不同的是:上一句只需更新主键索引树,这一句需要同时更新主键索引和索引c两棵索引树。 更新主键索引不会被锁住,锁住是因为需要更新 c 索引树(需要更新c=10的行)。- 如果去掉
desc,那么加锁范围就变成了(10,25],可以实验验证一下。
示例九:死锁
| sessionA | sessionB |
|---|---|
| begin; select * from t where c=10 lock in share mode; |
|
| update t set d=d+1 where c=10; | |
| insert into t values(8,8,8); | |
| Error 40001 1213 Deadlock found when trying to get lock; try restarting transaction |
-
sessionA 的第一条语句的加锁范围是
(5,10]+(10,15); -
毫无疑问sessionB 会被阻塞,但按理说 sessionB 此时应该还没有获取到任何锁,那么 sessionA 的第二条语句应该能执行才对,但是立马报了一个死锁错误?
实际上,
next-key lock的加锁分为两个阶段:先加间隙锁,再加行锁。sessionB 需要申请
(5,10]的next-key lock,会先加(5,10)的间隙锁,加锁成功;然后再加c=10的行锁,这时候才进入了锁等待。然后 sessionA 第二条语句被 sessionB
(5,10)的间隙锁锁住(),而 sessionB 又在等待 sessionA 释放c=10的行锁,于是出现了死锁。
所以,在分析加锁规则的时候可以用 next-key lock 来分析,但是要知道具体执行的时候是先加间隙锁,再加行锁。