解决的问题
-
脏读:读到还没有提交事务的数据
-
不可重复读:前后读取的记录内容不一致
-
幻读:同一事务前后两次查询同一范围数据时,后一次查询看到了前一次查询没有看到的行
主要针对
insert操作, 使用间隙锁解决,详见 MySQL学习笔记(八)-MySQL锁之next-key lock
隔离级别
- 读未提交
- 读提交:可解决脏读问题
- 可重复读:可解决不可重复读问题
- 串行化:事务都是串行执行,安全度最高,并发度最低
如何查询隔离级别?
1
show global variables like '%isolation%';

默认级别为可重复读。
如何更改隔离级别?
1
set global(session) transaction isolation level READ UNCOMMITTED ;
如何实现?
MVCC(Multiple Version Concurrency Control)多版本并发控制
简而言之,就是一行记录在数据库中存在多个版本,如下图所示:
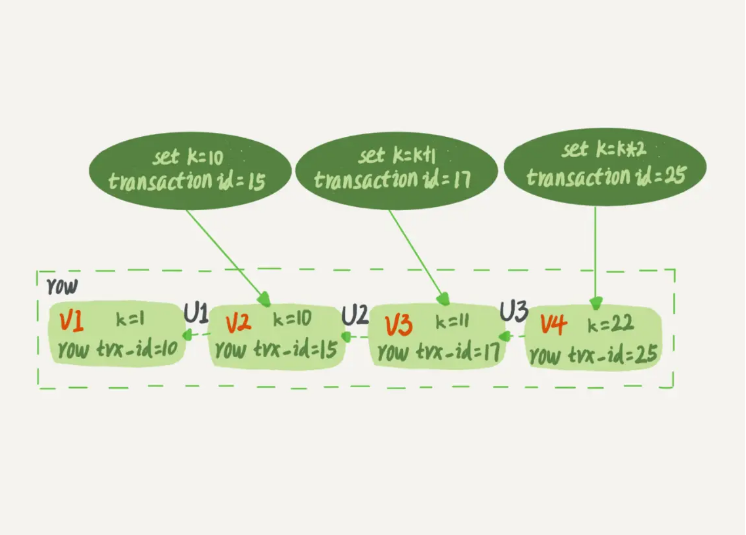
V1、V2、V3 并不是物理真实存在的,真实存在的是U1、U2、U3,也就是undo日志。当需要上一个版本的数据时,会通过当前记录和undo日志推算出来。其实每行记录都会有一个我们看不到的隐藏字段trx_id。
一致性视图(一致性读)
有两种开启事务的方式:
- begin/start transaction:并不是一个事务的真正起点,到执行第一个语句的时候才会创建一致性视图
- start transaction with consistent snapshot:马上开启事务并创建一致性视图
事务开启时,会创建一个一致性视图。不必纠结于视图两个字(其实就是个数组),可简单理解为这样一个操作:记录下真正开启事务的那一刻(创建一致性视图的那一刻),后面会以这个时刻为准来判断数据的哪个版本对于当前事务可见。
具体实现上,会在开启事务的那一刻生成一个数组,保存了当前系统正在活跃(启动了还没提交)的事务ID,定义一个低水位:数组里的最小事务ID,高水位:当前系统已经创建过的最大的事务ID+1,这个数组和高低水位即构成了一致性视图。后续的操作应该可以猜到,就是拿记录的事务ID和这个高低水位比较来判断是否可见。这是具体的代码逻辑,不方便记忆,可简化为下面的可见性规则(RR级别下):
- 本事务的更新总是可见
- 版本未提交,不可见
- 版本已提交,但是在一致性视图创建之后提交的,不可见
- 版本已提交,而且是在一致性视图创建之前提交的,可见
以上就是事务具体是如何实现的
不同隔离级别下的一致性视图生成时机
- 读未提交:直接读取记录的最新版本,没有视图的概念
- 读提交:每个语句会生成新的一致性视图
- 可重复读:在事务开启的时候生成一致性视图,在后续的整个事务期间都使用该视图
- 串行化:直接用加锁的方式来避免并行访问
当前读
事务使用的是一致性读,这里针对的是查询类操作,而更新类操作使用的是当前读,即读取记录的最新版本,这个区别这很重要。
示例一
千言万语,不如动手验证一下
假设存在表 t ( id, k) values (1,1) ( 2, 2),事务级别为默认级别,即可重复读。
| 事务A | 事务B | 事务C |
|---|---|---|
| start transaction with consistent snapshot; | ||
| start transaction with consistent snapshot; | ||
| update t set k=k+1 where id=1; | ||
| update t set k=k+1 where id=1; | ||
| select k from t where id=1; | ||
| select k from t where id=1; | ||
| commit; | ||
| commit; |
事务C没有显示开启事务,所以更新完成以后自动提交了,此时k的值是2。
先分析事务A,事务A最先开启,根据可重复读的一致性视图生成时机,在开启的那一刻创建了一致性视图,在此后的整个事务期间都使用该视图。又根据事务可见性规则,事务C的版本虽已提交,但是在视图创建之后提交的,不可见。事务B先不管值是多少,版本尚未提交,仍不可见。所以事务A的查询结果仍是1。
事务B首先执行了一次更新操作,这里的重点就是:此时读取的是哪个版本?结论是最新版本,即当前读。因为要保证更新不能丢失。所以读到的值是2,再+1=3。然后再进行一次查询操作,根据事务的可见性规则,本事务的更新总是可见。所以,事务B的查询结果是3。
如果换成读提交隔离级别,结果是怎样的?
根据读提交的一致性视图生成时机:在每一次执行语句的时候都生成新的视图,所以事务A的视图是在执行到 select 的时候生成。再根据事务的可见性规则,事务C的更新已提交,且是在视图生成之前提交,可见。事务B的更新尚未提交,不可见。所以事务A的查询结果是2。
事务B的查询结果还是3,分析过程和可重复读隔离级别下一样。
将上面的操作步骤稍微改一下,事务C稍后再提交,隔离级别仍是可重复读,看下结果会怎样
| 事务A | 事务B | 事务C |
|---|---|---|
| start transaction with consistent snapshot; | ||
| start transaction with consistent snapshot; | ||
| start transaction with consistent snapshot; | ||
| update t set k=k+1 where id=1; | ||
| update t set k=k+1 where id=1; | ||
| select k from t where id=1; | ||
| select k from t where id=1; | commit; | |
| commit; | ||
| commit; |
事务A查询结果:事务B和事务C的更新都尚未提交,不可见,结果是1。
事务B查询结果:重点来了,由于事务C更新后没有马上提交,所以id=1的写锁一直未释放。而事务B是当前读,必须要读最新版本,若读到的记录最终被回滚了,就产生了脏读,这是不可接受的,所以必须确保当前读读到的数据是最终会被提交的数据。具体实现就是加锁,来确保当前读的数据是最新的且已提交的(从事务的角度来解释行锁)。所以事务B的更新,要等待事务C提交后才能继续。
示例二
用事务的可见性来验证一个行为:更新的值与原来的值相同的情况下,MySQL还会执行更新吗?还是看到值相同直接返回了?
假设存在表 t(id,a),插入一条数据 (1,2)。
-
先验证是否还会加写锁(因为行锁是Innodb特有的,如果加写锁,说明还是会调用Innodb引擎的
update接口)sessionA sessionB begin; update t set a=2 where id = 1; update t set a=2 where id = 1; (blocked) sessionB的更新被阻塞,说明还是会加写锁。
-
再验证Innodb引擎是否会执行更新
注:此时
binlog_format为statment,binlog_format会影响结果,后面会详细分析sessionA sessionB begin; select * from t where id=1;
返回(1,2)update t set a=3 where id=1; update t set a=3 where id=1; select * from t where id=1;
返回(1,3)sessionA 的 update 是当前读,它肯定读到了 sessionB 更新后的最新版本,现在的问题是 sessionA 的这个 update 会不会执行更新?
根据事务的可见性规则,sessionA的第二个
select是看不到 sessionB 的更新的,但是它读取到的值却是(1,3),所以这个版本只能是本事务自己更新的,也就证明了sessionA中的update是执行了更新操作的。到这里可能会觉得这不是多此一举吗?判断一下值是否相等,相等的话就不用更新了。
事实上,是执行了判断的,只是这个判断没有办法判断出是否要执行更新。因为和具体的 sql 有关,在这句sql里:
set a=3,这个赋值操作和a原本的值没有任何关系,所以虽然update是当前读,但因为和a没有关系,就不会读出a的值。既然没有a的值,就没有办法判断是否和原值相等,所以只能老老实实执行一遍更新操作。可将sessionA的
update where条件加上a=3,此时因为读出了a的值,Innodb判断到值是相同的,就不会执行更新操作。因此第二个select还是读取的一致性视图,返回(1,2):sessionA sessionB begin; select * from t where id=1;
返回(1,2)update t set a=3 where id=1; update t set a=3 where id=1 and a=3; select * from t where id=1;
返回(1,2)这个实验也可以得出一个结论:
update虽然都是当前读,但不一定都会执行更新操作。上面说过,
binlog_format会影响结果,将binlog_format改为row后,会发现 sessionA 的第二个select读取到的都是(1,2)。这是因为row格式的binlog记录的是行数据的变更,需要拿到所有字段,拿到所有字段后就可以进行判断,发现值相同便不执行更新操作,所以 sessionA 的第二个select读取到的还是一致性视图中的(1,2)。
长事务
尽量避免长事务,长事务有以下风险:
-
会产生大量undo日志,会占用大量存储空间。在MySQL 5.5 及以前版本中,回滚日志是和数据字典一起放在ibdata文件中的,即使长事务最终被提交,回滚日志被清理,文件也不会变小。
-
还会占用锁,可能拖垮整个库。在 RR 级别下,所有锁资源要在事务提交后才释放。
-
由于undo日志太多,导致需要快照读的查询变得很慢
如这个例子:
1 2
select * from t where id=1; select * from t where id=1 lock in share mode;
按理说,第二句还需要加锁,应该是第一句更快点,而结果却是(慢查询日志):


第一句查询需要800ms,第二句只需要0.2ms,为什么有这么大的差距?
其实它们的执行序列是这样的:
sessionA sessionB start transaction with consistent snapshot; #执行100万次
update t set c=c+1 where id=1;select * from id=1; select * from id=1 lock in share mode; 所以很明显,
sessionB产生了大量的回滚日志,而select * from id=1 lock in share mode是当前读 ,读取的是最新版本,所以很快。而select * from id=1是快照读,需要从当前版本应用100万次回滚日志得到最初的版本,因此自然慢多了。 -
甚至可能会导致优化器选错索引。
案例重现:
表
t定义如下:1 2 3 4 5 6 7 8
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `a` (`a`), KEY `b` (`b`) ) ENGINE=InnoDB;
存储过程,插入100000条数据:
1 2 3 4 5 6 7 8 9 10 11 12
delimiter ;; create procedure idata() begin declare i int; set i=1; while(i<=100000)do insert into t(a,b) values(i, i); set i=i+1; end while; end;; delimiter ; call idata();
插入数据后执行
select * from t where a between 10000 and 20000,查询走的是a索引,没有问题1
explain select * from t where a between 10000 and 20000

sessionA模拟一个长事务,sessionB先清空表,再调用存储过程插入数据sessionA sessionB start transaction with consistent snapshot; delete from t; call idata(); explain select * from t where a between 10000 and 20000; commit 再查看执行计划,会发现没有选择使用索引
a,走的是全表扫描
为什么?
选择索引是优化器的工作,它会综合考虑扫描行数、索引基数、是否使用了临时文件、是否排序等因素来选择它认为速度最快的索引。
可通过
show index from t来查看索引基数 cardinality (近似值,并不精确),结果如下:
索引基数越大,说明区分度越高,选择它的概率就越大。图中可以看出主键和
a的差距并不大,a反而是最高的,不选择索引a肯定还有其他的原因。再来看一下扫描行数。查询计划显示走的是全表扫描,rows为105033行。强制使用索引
a看下扫描行数是多少:1
explain select * from t force index(a) where a between 10000 and 20000;

rows为39940行。这个差距挺大的,那为什么优化器放着 39940行的
a索引不用而要选择 105033行的全表扫描?因为使用索引
a需要回表,而走全表扫描是直接扫描主键索引树,不需要回表,优化器”认为“全表扫描更快。从结果上看,优化器明显选错了,所以优化器也不是百分百可靠的。到这里又有一个疑问,为什么开启了一个长事务后,删除再插入数据就会导致扫描行数发生变化?
很明显,肯定和这个长事务有关。
先简单说一下
undo log,分为两种:insert undo logs和update undo logs,对应 insert操作和update、delete操作(delete本质上也是update操作,delete时并不是直接物理删除,而是先做一个deleted标记)。insert undo logs只用于回滚操作,并且在事务提交后便可清除(事务提交即意味着插入已永久持久化了,不会再有回滚操作,也就不再需要 insert undo logs 了)。而update undo logs除了用于回滚操作之外,还用于MVCC,且当没有在该事务开启之前开启的其他事务在运行时,方可删除。上面讲到 delete 时并不是直接物理删除,而是先标记。只有在对应的
update undo logs被清除时才会进行真正的物理删除,这个过程也称为purge。所以在这个案例中,因为先开启了一个长事务
sessionA,为了保证事务的可重复读,在sessionB中进行的 delete 和 insert 操作所产生的upodate undo logs会一直保留直到长事务提交。也就意味着原先的10万行数据并没有被真正删除,而是保留在了索引树上。因此每一行都会有两个版本,即总共会有20万数据,从 ibd 文件大小也能看出,大小变为了原来的两倍。而优化器统计扫描行数时会将标记为删除的版本也统计在内,导致扫描行数增加。那为什么只有索引
a的扫描行数增加了,主键的扫描行数还是10万行?因为主键的扫描行数是直接按照表的行数来估算的,而表的行数优化器取的是show table status like 't'中rows的值。索引的统计则是通过对数据页采样统计估算出来的,所以会算上老版本的数据。原因找到了,如何解决?
- 既然是由长事务引起的,提交或kill掉长事务后便可重新让查询走索引
a - 简单粗暴,
force index(a)强制使用索引a` analyze table t重新统计索引信息,优化器会更正扫描行数,然后选择使用索引a。当发现 explain 预估的 rows 和实际情况差距较大时,都可以采用这个方法来处理
- 既然是由长事务引起的,提交或kill掉长事务后便可重新让查询走索引
如何监控长事务?
下述语句用于监测持续时间超过60s的长事务
1
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
如何避免长事务?
应用开发端
-
确认是否使用了
set autocommit = 0,代表手动提交事物。可先开启general_log,通过show global variables like '%general_log%'查看general_log相关设置。然后随便跑一个业务逻辑,在日志中检查是否有set autocommit = 0;The general query log is a general record of what mysqld is doing. The server writes information to this log when clients connect or disconnect, and it logs each SQL statement received from clients. The general query log can be very useful when you suspect an error in a client and want to know exactly what the client sent to mysqld.
-
确认是否有不必要的只读事务。有些框架会不管什么语句都用
begin/commit包起来。或者有些业务并没什么必要,也要把一堆select放到事务中。上面提到过,对当前读事务会加锁。所以对于单纯的select没有必要放到事务中,事务中主要放update/insert/delete,除非是明确需要事务特性的查询,比如明确需要可重复读的查询,才需要放到事务中; -
根据对业务的预估,通过
set max_execution_time来设置单个语句的最长执行时间,来避免单个语句意外执行过长时间。毫秒,0 表示未启用。
数据库端
-
监控
information_schema.innodb_trx表,超过阈值就报警或者kill掉。 -
推荐使用
percona 的 pt-kill工具,作用描述如下:pt-kill captures queries from SHOW PROCESSLIST, filters them, and then either kills or prints them. This is also known as a “slow query sniper” in some circles. The idea is to watch for queries that might be consuming too many resources, and kill them.
-
在测试阶段可要求输出所有的
general_log,分析日志提前发现问题。 -
在MySQL5.6或更新版本,可将
innodb_undo_tablespaces设置为 2 或更大的值,如果真的出现大事务导致回滚段过大,清理起来更方便。innodb_undo_tablespaces:- 0:使用系统表空间,即 ibdata1
- 不为0:使用独立数量的undo表空间,默认为2,即存在两个独立的回滚表空间: undo_001、undo_002