binlog
MySQL Server层的日志,与存储引擎无关。
主要作用:
- WAL
- 如果是 Innodb 引擎,和 redo log 一起提供崩溃恢复的能力(crash-safe),保证了事务ACID中的持久性
- 数据恢复,比如误删
- 常被用于主备同步,或接入其他下游系统如 es 用于数据分析,即作为其他需要直接从数据库获取数据且有很高实时性要求的下游系统数据来源通道
如何查看?
-
查看binlog 格式
1
show global variables like '%binlog_format%';
-
查看当前使用的binlog文件
1
show master status ;
-
查看所有binlog文件
1
show binary logs;
-
查看binlong文件内容
方式一:show 命令
1
show binlog events in 'binlog.000008';
方式二: mysqlbinlog
1
mysqlbinlog --base64-output="decode-rows" --verbose binlog.000001
-
binlog 3种格式的区别
STATEMENT:记录具体执行语句,如
update t set name = 'newName' where name = 'oldName'ROW:记录每一行记录的变更,一条
update语句可能产生多条日志(每条记录都会产生一行日志)MIXED:MySQL会根据当前执行语句判断使用
STATEMENT还是ROW -
选择哪种格式?
-
STATEMENT:直接记录sql,可能会在某些情况下导致通过日志恢复出来的数据不一致,比如 RC 和 RR 在锁问题上的区别、更新的值与原来的值相同的情况下,MySQL还会执行更新吗?、delete+limit时走的索引不同会导致删除的记录不同、一些函数结果不同等等delete+limit时走的索引不同会导致删除的记录不同:假设存在表:t( id int, a int , created_time date),id 是主键,a上有索引
有以下数据:
(1, 1, ‘2022-01-01’)
(2, 2, ‘2022-01-03’)
(3, 3, ‘2022-01-02’)
sql:
delete from t where a>=2 and created_time<='2022-01-03' limit 1如果主库走的是索引a,则会删除 id=2 的记录。如果备库走的是索引 created_time,则会删除 id=3 的记录。
-
ROW: 直接记录每一行记录的变更,最安全,但是日志的量会很大,MySQL 8 默认格式就是ROW -
MIXED: 会根据当前执行语句判断使用STATEMENT还是ROW,比如上面那条 delete+limit 的语句就会切换到使用 ROW 格式的binlog。推荐采用这种格式。
-
-
切换当前连接 binlog 格式
1
SET SESSION binlog_format = 'STATEMENT';
-
刷新binlog
1
flush logs;
binlog的写入时机
binlog会首先写到cache里,cache满了就会执行sync_binlog。这个参数大小由 binlog_cache_size 控制,默认是32K。注意这个cache是单个线程拥有的,也就是说每个线程都有自己的binlog_cache,但是共用同一份binlog文件。
一个事务的binlog是不能被拆开的,无论一个事务多大,也要确保一次性写入binlog文件。
binlog会被首先write到操作系统的page cache中,然后才会被 fsync到磁盘中。一般可认为只有fsync才占磁盘的IOPS。
write 和 fsync 的时机由参数 sync_binlog控制,默认值是1,总共有3种设置:
-
0:每次事务提交时都只write,不fsync。由于只保存到操作系统缓存,依赖操作系统来时不时的fsync,如果主机掉电或崩溃会丢失binlog
-
1:每次事务都 fsync
-
N(N>1):每次事务提交都write,但只有累计了 N 个事务以后才会 fsync,如果主机掉电或崩溃会丢失最近N个事务的binlog
redo log
Innodb 特有的日志,存储的是物理日志,即数据页上的改动。
数据页:Innodb 从磁盘读取数据的基本单位,即使只取一行记录,也会将改行所在的整个数据页读入内存。数据页的大小可通过以下参数查看,默认为16k
1
show global variables like 'innodb_page_size';
主要作用:提供事务能力,保证 crash-safe
redo log 格式
采用循环写的方式,有2个游标:checkpoint、writepos。writepos 表示当前写的位置,checkpoint 表示要擦除的位置,都是边写边往后推移。
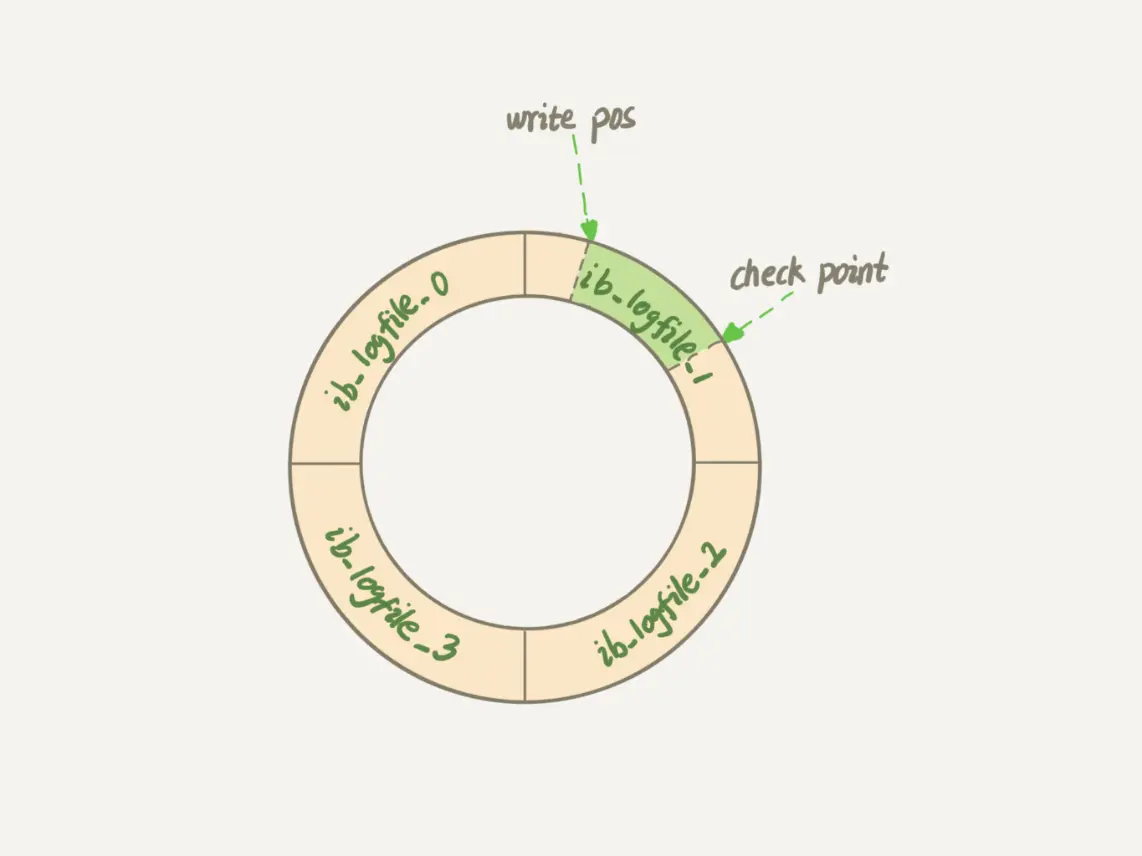
这个图画的不太好,一开始 checkpoint 和 writepos 都处于同一位置,边写边往后推移。上图可理解为:两者一开始都处于 checkpoint 现在的位置,writepos 写了一圈又转到 checkpoint 后面了。 所以绿色的部分表示空闲的空间,黄色的表示已写的空间。
查看 redo log 相关设置
1
show global variables like '%innodb_log%';
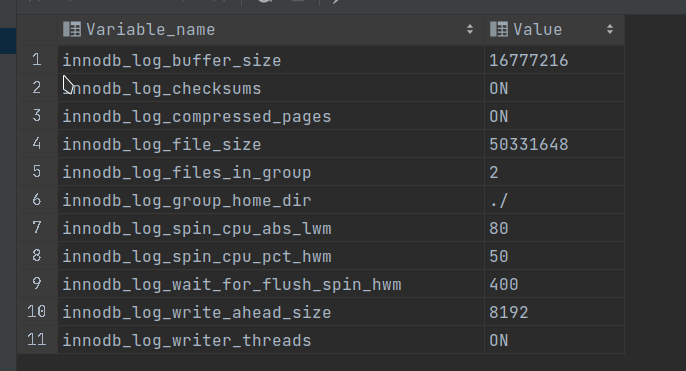
innodb_log_buffer_size:redo log 缓冲区大小,默认16M
innodb_log_file_size:redo log文件大小,默认48M
innodb_log_files_in_group:每组有多少个redo log 文件,默认2个:ib_logfile0、ib_logfile1
redo log 一般设多大?
redo log 太小的话,会导致很快被写满,然后不得不强行刷 redo log,发挥不出 WAL 的作用。
所以,磁盘空间不是很紧张的话,设大点吧,比如设置为4个文件,每个文件1G。
redo log 的写入时机?
同样,redo log 也分为 write 和 fsync,由参数 innodb_flush_log_at_trx_commit控制,默认值为1:
-
0:只把 redo log 写到 redo log buffer 中,后台线程每隔1s会将 buffer 中的内容 write、fsync 到磁盘
如果 MySQL 崩溃,会丢失1s的事务数据
-
1:每次事务提交都 fsync 到磁盘
最安全,严格保证了事务的持久性,只要事务提交成功,就说明对应的日志已落盘
-
2:每次事务提交都只将redo log 写到 page cache 中,后台线程每隔1s会将 page cache 中的内容 fsync 到磁盘
如果主机掉电或异常重启,会丢失1s的事务数据
0 和 2 的区别在于,0是写到了 redo log buffer 中,属于 MySQL 管理的内存。2是写到了 page cache 中,属于操作系统的内存。
可靠性 1 最高,性能 0和2 最好(2 可靠性要比 0 高,因为主机重启的概率一般比MySQL崩溃的概率低,二者选一的话,建议设置为2)。
没提交的事务也会被 被动的 写入磁盘:
- redo log buffer 占用空间达到
innodb_log_buffer_size一半时,后台线程会主动写盘,注意由于没有提交事务,此时只是 write,没有 fsync - 如果有并行事务,假如A执行了一半,已经写了一些redo log 到 buffer中,此时 B 提交,如果
innodb_flush_log_at_trx_commit=1,B要把buffer里日志全部fsync到磁盘,此时会带上A的内容一起fsync
参考:mysql8 doc innodb_flush_log_at_trx_commit
最终数据落盘的过程是?
1、正常运行过程中,MySQL更新完内存后便可返回响应(首先会把该记录所在数据页读到内存中,如果发现有对应 redo_log 存在,则需要将redo_log中的内容应用到从数据页)。
此时内存中的数据页被称为脏页,最终数据落盘就是把脏页写盘,这个过程和redo log 毫无关系(后台有定时任务:purge,会定期执行这个刷脏页的操作)。当然,此时 redo log 中已经记录了相关数据页的改动。写盘的时候还会向前推进redo log 中 checkpoint 的位置。
2、在崩溃恢复时或启动时(MySQL启动时会自动执行该过程),会先将 redo log 中记录的变更应用到内存数据页中,此时该数据页就变成了脏页,接下来的步骤就和第1种情况一样了。
两阶段提交
一个事务当写完内存和redo log、binlog以后就算提交成功了,并不需要写真正的数据文件。为了保证2个日志文件都写入成功,采用了两阶段提交的方法,如下图所示

两阶段提交并不是MySQL特有的,它是一种通用的分布式处理策略。其本质说来也很直白,就是一个人的时候好办,人多的时候,为了保持大家步调一致,每个人准备好以后吼一声,都准备好了再继续下一步。
这里有个细节,当 innodb_flush_log_at_trx_commit=1 时,在redo log的 prepare 阶段就会fsync一次。然后再写binlog,再将redo log 的标识设为 commit(但是这个阶段只会write,不再需要fsync了,因为有后台定时线程:每1秒会fsync一次;和崩溃恢复逻辑:prepare的redo log 加上完整的binlog即可保证事务的持久性和一致性)
两阶段提交如何保证 crash-safe?
crash-safe具体提供了什么能力?
- 只要客户端收到事务成功的消息,事务就一定持久化了
- 只要客户端收到事务失败的消息,事务就一定失败了
- 如果客户端收到“执行异常”之类的消息,需要应用重连后查询当前状态来执行后续逻辑。数据库内部只要保证数据和日志、主库和备库之间一致就行了
具体如何实现?
在崩溃恢复时,检查 redo log 和 binlog 的状态,如果:
1、redo log 状态为commit,直接提交事务
2、redo log 状态为prepare,查看对于的binlog是否完整:
a. 不完整,回滚
b. 完整,提交事务
如何知道binlog是否完整?
完整的binlog最后会有个 XID EVENT 和 COMMIT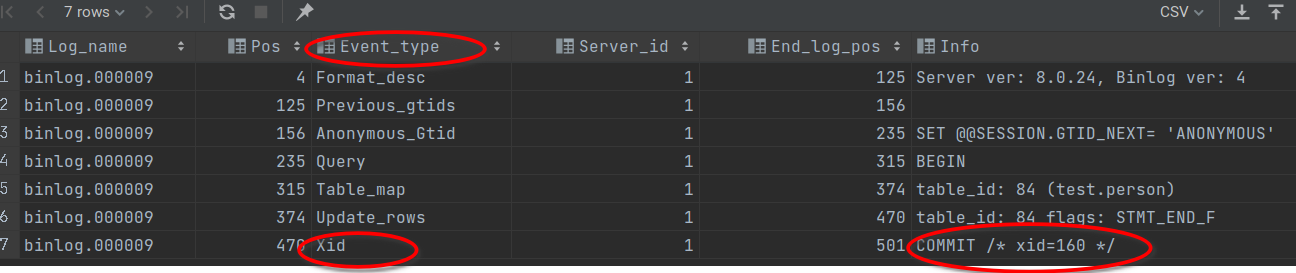
此外,还提供了一个 binlog-checksum 参数用于校验binlog的完整性。
redo log 是怎么和 binlog 对应起来的?
它们都有一个共同的字段 XID
为什么要引入两个日志,只用binlog 不就行了?
很重要的一点:binlog不具备 crash-safe 的能力。
1、binlog 中没有checkpoint,不能区分哪些是已经落盘到磁盘数据文件(即最终存储数据的文件),哪些是需要应用到内存中用于崩溃恢复的
2、binlog中存储的是逻辑日志,即sql级别的语句。redo-log中存储的是物理日志,即数据页级别的改动。一个sql语句可能会更改到好几个数据页,如果单个数据页损坏,binlog是没有能力恢复单个数据页的,它只能应用整个sql语句。比如一个sql语句同时更改了ABC三个数据页,更新的时候发生了crash,B数据页没有正常更新,AC正常更新。如果使用binlog来恢复,它只能同时恢复ABC三个数据页,结果就是B恢复了,AC又不对了。简而言之,binlog粒度太大。
为什么要写2个日志,直接更新数据文件不是更快吗?
这种思路叫做 write ahead log,简称 WAL,是数据库的通用技术,主要基于以下两点:
-
顺序写快于随机写。写日志文件都是顺序写,而直接更新数据文件大多数都是随机写,在机械硬盘时代这个速度差异非常大。
-
虽然是写2个日志,看似意味着一次事务提交要经历两次刷盘,实际上利用了
组提交的策略,fsync 的次数会大大减少,而write 到 操作系统page cache 基本上可以认为和写到内存差不多,可认为只有 fsync 会占用磁盘的 IOPS。
组提交
两阶段提交更细化一下,其实是下图这个步骤:
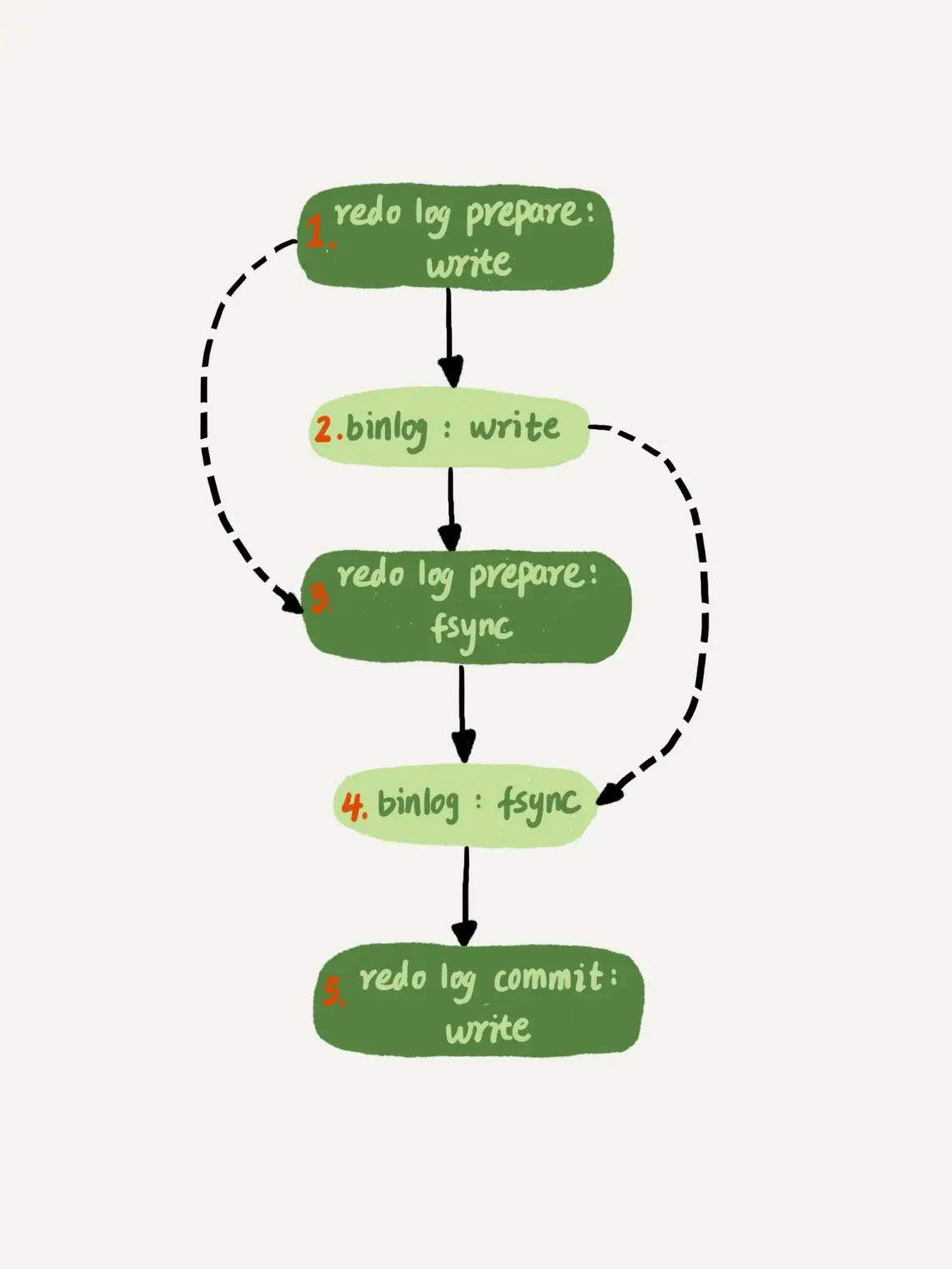
对应第2步,由于redo log write 完之后没有立即 fsync,而是等了一步:等binlog write完,所以有机会可以积累更多的redo log 到 page cache中,然后再一并进行 fsync。
对应第4步,binlog fsync 之前要等待redo log fsync。但是由于通常情况下 redo log fsync会很快,所以binlog 组提交的效果不如 redo log 的明显。但是可以通过调整以下参数优化:
binlog_group_commit_sync_delay:表示延迟多少微秒以后才调用 fsync
binlog_group_commit_no_delay_count:表示积累多少次以后才调用 fsync
两者是或的关系,当第一个参数为0时,表示不延迟,直接fsync,状态为true,则不再考虑第二个参数的设置了。
组提交与 sync_binlog 不冲突,可一起使用。
参考:mysql8 doc binlog_group_commit_sync_delay
如何提高MySQL的IO性能?
从提高写redo log 和 binlog 的性能入手。
redo log:
-
增大redo log buffer 大小
尤其对于需要更新很多行的大事务,大的redo log buffer 意味着事务提交前不会由于buffer满了而需要先写到磁盘上
-
增大redo log file 大小和个数
-
将
innodb_flush_log_at_trx_commt设为2,表示每次事务提交都只 write 到 page cache,由后台定时线程来fsync。这样做的风险是主机掉电重启后会丢失数据(正常关闭不影响,MySQL在正常关闭前会完成一系列收尾工作)
参考:Optimizing InnoDB Redo Logging
binlog:
-
将
sync_binlog设为大于1的值(通常是100-1000),这样做的风险是主机掉电会丢失binlog日志 -
调整
binlog_group_commit_sync_delay和binlog_group_commit_no_delay_count,提高binlog组提交效率,减少写盘次数。这样做会增加语句的响应时间,但是不会有丢失数据的风险
增大 buffer pool 大小:
buffer pool 是用来缓存表数据的内存,默认值是128M,增大这个值可以显著减少磁盘IO。
如果是数据库专用服务器,可以把 buffer pool 设为物理内存的 80%。
当 buffer pool 大小超过1G,建议同时把 innodb_buffer_pool_instances 设为大于1的值。相当于把 buffer pool 划分为了多个区域,可提高并发度。
参考:mysql8 doc innodb_buffer_pool_size
sql语句突然变慢了?
有时会遇到这种情况,一条sql平时执行都很快,但有时候不知道为什么突然就变得很慢,而且这个情况还是随机的、持续时间也很短,很难复现。
突然变慢的这一瞬间很有可能是MySQL在刷脏页。
以下4种情况会引发刷脏页:
- 当需要读入新的内存页时,如果系统内存不足,就需要淘汰旧的数据页。如果淘汰的是脏页,就需要把脏页刷到磁盘。当一次淘汰的脏页太多时,就会明显影响性能。
- redo log 写满了。此时需要把 checkpoint 到 write pos 之间的redo log对应的脏页刷到磁盘,并把 checkpoint 往前推进。这种情况是很严重的,此时MySQL将不再接受更新,所有更新都会堵住。
- 后台任务
purge会在系统空闲时刷脏页。 - MySQL正常关闭时。
解决思路:
主要解决前两种情况,后两种情况不会影响到系统性能。
对于情况二,调整 redo log 的大小即可,默认值明显太小,上文有讲过。
对于情况一,除了上面提到过的 buffer pool,还需要先了解下Innodb刷脏页的控制策略和相关参数。
这里主要的参数是 innodb_io_capacity,从名字就可以看出是控制 IO 能力的,官方描述如下:
The
innodb_io_capacityvariable defines the number of I/O operations per second (IOPS) available toInnoDBbackground tasks, such as flushing pages from the buffer pool and merging data from the change buffer.
简单说就是设置 IOPS,它用来告诉 Innodb 所在主机的 IO 能力,用于后台任务刷脏页和 change buffer 的 merge。默认值是200,即 Innodb 全力刷脏页可以达到 200 IOPS。这个值明显太低了,即便是对于机械硬盘。
当然,Innodb 不会完全按照这个值去刷脏页,因为系统还需要处理服务请求。Innodb的做法是会算出一个百分比,然后按 innodb_io_capacity 定义的能力乘以这个百分比来控制刷脏页的速度。
百分比的大致算法:
-
根据当前脏页比例再结合
innodb_max_dirty_pages_pct(脏页比例上限,默认值是90)算出一个 0到100 之间的数字脏页比例可通过下面命令得到:
1 2 3
select VARIABLE_VALUE into @a from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty'; select VARIABLE_VALUE into @b from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_total'; select @a/@b;
计算方法伪代码如下,M 为当前脏页比例:
1 2 3 4 5 6
F1(M) { if M>=innodb_max_dirty_pages_pct then return 100; return 100*M/innodb_max_dirty_pages_pct; }
-
InnoDB 每次写入的日志都有一个序号(LSN),当前写入的序号跟 checkpoint 对应的序号之间的差值,假设为 N。InnoDB 会根据这个 N 算出一个范围在 0 到 100 之间的数字,N 越大,算出来的值越大。
-
取2值较大者作为百分比
从这个过程可以看出,可以介入的部分就是两个参数:innodb_io_capacity 和 innodb_max_dirty_pages_pct。
-
innodb_io_capacity建议设置为磁盘的IOPS,磁盘的IOPS可以通过下面的命令来测试,一般参考测试结果中 write 的能力来设置:
1
fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytest
注意:一定要熟悉
fio的使用方法,否则可能会把盘都刷了!!!注意,注意,注意,危险的事情说三遍!!!参考:fio 命令入门到跑路
-
innodb_max_dirty_pages_pct从上面的伪代码可以看出,当脏页比例≥该参数值时,第一个参数为100;否则取脏页比例/该参数值的百分比。MySQL8.0以后该值默认为90,也就是说当脏页比例≥90时,会百分百按
innodb_io_capacity的能力全力刷脏页。为了尽量避免因刷脏页引起的抖动,应经常关注脏页比例,不要让它经常接近90%。或者可以调高一点(其实该值已经调整过了,之前是75,8.0后调为了90。90已经接近100了,可认为该值是一个很合理的值,如果脏页累计过多,刷脏页就会很频繁)。
除此之外,还有一个参数 innodb_flush_neighors,从参数名字可以看出大概意思:刷脏页的时候是只刷自己还是连着附近的脏页也一起刷了,1表示启用,0表示只刷自己。
这个机制对于传统机械硬盘很有用,机械硬盘的IOPS一般只有几百,每次多刷一些可以减少很多随机IO。而SSD的随机IO已不是瓶颈,只刷自己反而会更快些。在MySQL8.0中,该参数的默认值已为0,表示只刷自己。