首先看实体,Organization
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
package com.example.organization.domain.repo.po;
import lombok.Getter;
import lombok.Setter;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.*;
import java.util.Objects;
import java.util.Set;
@Entity
@Table(name = "organization")
@Getter
@Setter
public class OrganizationPo {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
@Column(name = "org_id")
private String orgId;
@Column(name = "org_name")
private String orgName;
@ManyToOne
@JoinColumn(name = "parent_id", referencedColumnName = "org_id")
private OrganizationPo parent;
@OneToMany(mappedBy = "parent")
private Set<OrganizationPo> children;
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
OrganizationPo that = (OrganizationPo) o;
return orgId.equals(that.orgId);
}
@Override
public int hashCode() {
return Objects.hash(orgId);
}
}
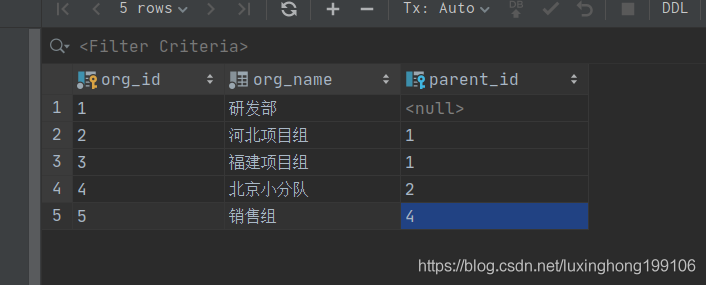
这是一个双向自关联的实体。表数据如下:
对于 @OneToMany 默认fetch策略是 Lazy,也就是在实际访问到 children 属性时才会发出数据库请求,比如你打了断点调试,查看 children 属性时,或者 @ResponseBody 序列化到前端时才会发出新的查询。
注意不要使用 lombok 的 @Data,会有带上所有字段的 toString() 方法,此时debug的时候会因为调用 toString() 而导致循环引用从而抛出 stackoverflowError,使用默认的 toString() 就好,默认的 toString() 采用的是 hashCode 的16进制。
接下来需要做 po(persistence object)到do(domain object)、do到dto(data transfer object) 的转换,此时依旧会出现循环引用、堆栈溢出的问题。do实体如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
package com.example.organization.domain.aggregate;
import lombok.Getter;
import lombok.Setter;
import java.util.Objects;
import java.util.Set;
@Getter
@Setter
public class Organization {
private String orgId;
private String orgName;
private Organization parent;
private Set<Organization> children;
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Organization that = (Organization) o;
return orgId.equals(that.orgId);
}
@Override
public int hashCode() {
return Objects.hash(orgId);
}
}
我采用的 bean mapping 工具是 mapstruct ,各方面都较优的一个映射工具,它提供的解决方案是:
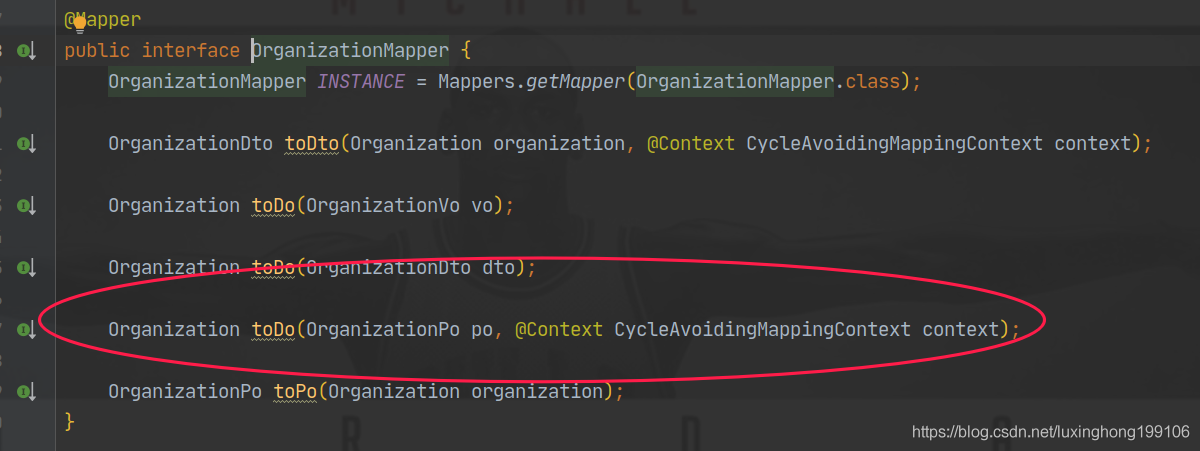
CycleAvoidingMappingContext 如下:
1
2
3
4
5
6
7
8
9
10
11
12
public class CycleAvoidingMappingContext {
private Map<Object, Object> knownInstances = new IdentityHashMap<Object, Object>();
@BeforeMapping
public <T> T getMappedInstance(Object source, @TargetType Class<T> targetType) {
return (T) knownInstances.get(source);
}
@BeforeMapping
public void storeMappedInstance(Object source, @MappingTarget Object target) {
knownInstances.put(source, target);
}
}
使用方式:
1
2
3
private static Organization toDo(OrganizationPo po) {
return OrganizationMapper.INSTANCE.toDo(po, new CycleAvoidingMappingContext());
}
原理就是以已经映射过的 po 为 key,do 为 value,存到一个 map 里。在递归设值的过程中,再遇到同一个 po,就可以直接从 map 中取出对应的 do,从而避免了无限循环。
最后到了序列化的阶段,此时仍然有循环引用的问题。springboot 默认采用的是 jackson 框架,jackson 提供了一个注解可以解决此问题:
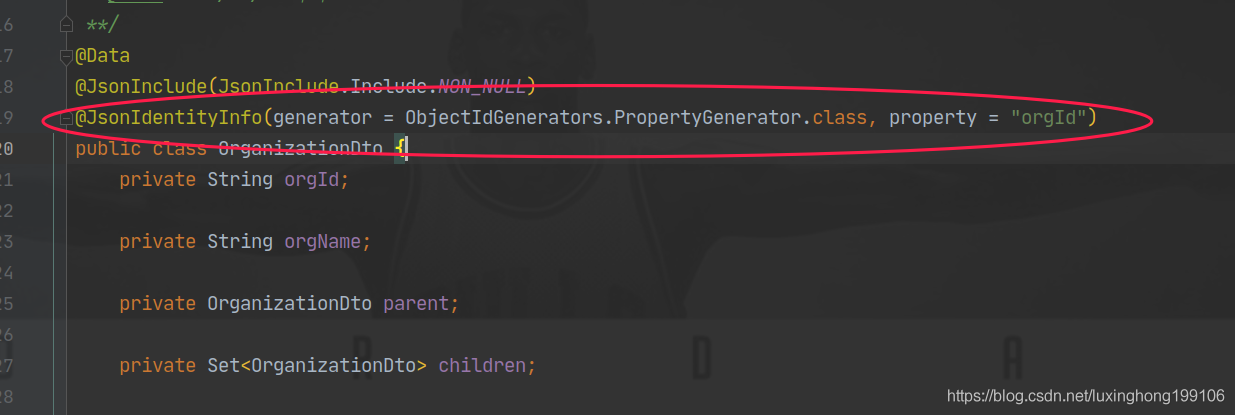
意思就是对于相同的对象,直接使用 orgId 属性表示。最后假如执行 dao.findById("1"),返回的结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
{
"orgId": "1",
"orgName": "研发部",
"children": [
{
"orgId": "2",
"orgName": "河北项目组",
"parent": "1",
"children": [
{
"orgId": "4",
"orgName": "北京小分队",
"parent": "2",
"children": [
{
"orgId": "5",
"orgName": "销售组",
"parent": "4",
"children": [
]
}
]
}
]
},
{
"orgId": "3",
"orgName": "福建项目组",
"parent": "1",
"children": [
]
}
]
}
可以看到解决循环引用的思路都是想办法切断循环引用,一个是返回已有的对象,一个是用其他属性表示,都可以终止递归调用。